
Flume
Flume是一个海量日志采集、聚合和传输的日志收集系统。
Kafka是一个可持久化的分布式的消息队列。
由于采集和处理数据的速度不一定同步,所以使用Kafka这个消息中间件来缓冲,如果你收集了日志后,想输出到多个业务方也可结合Kafka,Kafka支持多个业务来读取数据。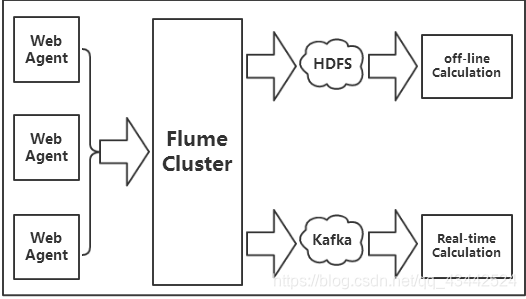
上图中Kafka生产的数据,是由Flume提供的,这里我们需要用到Flume集群,通过Flume集群将Agent的日志收集分发到Kafka(供实时计算处理)和HDFS(离线计算处理)。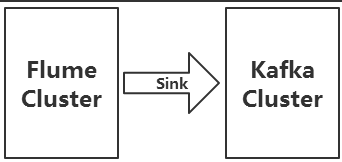
Flume将收集到的数据输送到Kafka中间件,以供Storm去实时消费计算,整个流程从各个Web节点上,通过Flume的Agent代理收集日志,然后汇总到Flume集群,再由Flume的Sink将日志输送到Kafka集群,完成数据的传输流程。
#定义各个组件
agent1.sources = src
agent1.channels = ch_hdfs ch_kafka
agent1.sinks = des_hdfs des_kafka
#配置source
agent1.sources.src.type = syslogtcp
agent1.sources.src.bind = localhost
agent1.sources.src.port = 6666
#配置channel
agent1.channels.ch_hdfs.type = memory
agent1.channels.ch_kafka.type = memory
#配置hdfs sink
agent1.sinks.des_hdfs.type = hdfs
agent1.sinks.des_hdfs.hdfs.path = hdfs://localhost:9000/myflume/syslog_mem_hdfsandkafka/
agent1.sinks.des_hdfs.hdfs.useLocalTimeStamp = true
#设置flume临时文件的前缀为 . 或 _ 在hive加载时,会忽略此文件。
agent1.sinks.des_hdfs.hdfs.inUsePrefix=_
#设置flume写入文件的前缀是什么
agent1.sinks.des_hdfs.hdfs.filePrefix = q7
agent1.sinks.des_hdfs.hdfs.fileType = DataStream
agent1.sinks.des_hdfs.hdfs.writeFormat = Text
#hdfs创建多久会新建一个文件,0为不基于时间判断,单位为秒
agent1.sinks.des_hdfs.hdfs.rollInterval = 20
#hdfs写入的文件达到多大时,创建新文件 0为不基于空间大小,单位B
agent1.sinks.des_hdfs.hdfs.rollSize = 10
#hdfs有多少条消息记录时,创建文件,0为不基于条数判断
agent1.sinks.des_hdfs.hdfs.rollCount = 5
#hdfs空闲多久就新建一个文件,单位秒
agent1.sinks.des_hdfs.hdfs.idleTimeout = 20
#配置kafka sink
agent1.sinks.des_kafka.type = org.apache.flume.sink.kafka.KafkaSink
agent1.sinks.des_kafka.brokerList = localhost:9092
agent1.sinks.des_kafka.topic = flumekafka
agent1.sinks.des_kafka.batchSize=100
agent1.sinks.des_kafka.requiredAcks=1
##下面是把上面设置的组件关联起来(把点用线连起来)
agent1.sources.src.channels = ch_hdfs ch_kafka
agent1.sinks.des_hdfs.channel = ch_hdfs
agent1.sinks.des_kafka.channel = ch_kafka
启动kafka-server