
为什么用Flume:

可靠性:

Flume是Cloudera公司的一款高性能、高可用的分布式日志收集系统。
Flume的核心是把数据从数据源收集过来再送到目的地。为了保证输送一定成功,在送到目的地之前,会先缓存数据,待数据真正到达目的地后,再删除缓存的数据。
Flume传输数据的基本单位是event,如果是文本文件,通常是一行记录,这也是事务的基本单位。
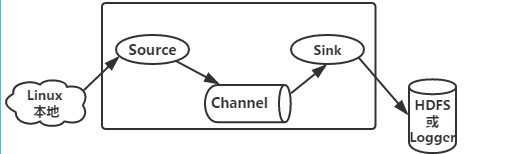
Flume运行的核心是Agent。它是一个完整的数据收集工具,含有三个核心组件,分别是Source、Channel、Sink。
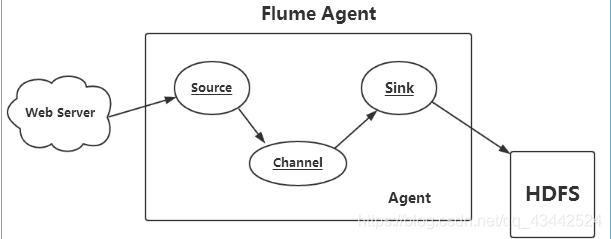
Source组件是专门用于收集日志的,可以处理各种类型各种格式的日志数据,包括Avro、Thrift、Exec、Jms、Spooling directory、Netcat、Sequence Generator、Syslog、HTTP、Legacy、自定义。
Source组件把数据收集来以后,临时存放在Channel中。
Channel组件是在Agent中专门用于临时存储数据的,Source收集的数据将临时储蓄于此,可以存放在Memory、Jdbc、File、自定义。
Channel中的数据只有在Sink发送成功之后才会被删除。
Sink组件是用于把Channel中数据发送到目的地的组件,目的地包括HDFS、Logger、Avro、Thrift、Ipc、File、Null、HBase、Solr、自定义。
在整个数据传输过程中,流动的是event。事务保证是在event级别。
Flume配置:Source、Channel、Sink
Source的类型主要有:Exec、Avro、Netcat、Spooldir、 Http 、Syslogtcp 、Seq、Thrift等。
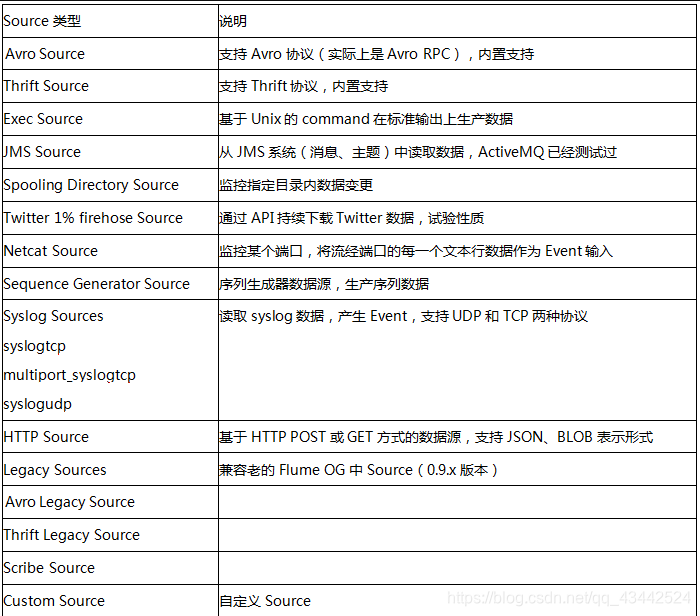
Channel的类型主要有File、 Memory 、JDBC等。
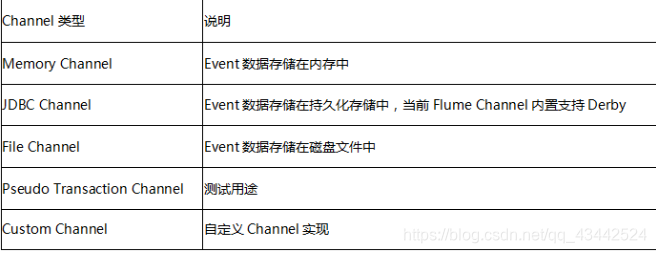
Sink的类型主要有:Null、HDFS、 HBase、 Hive、Thrift、 Avro、Logger等。
执行代码:
下面我们令Source为exec类型,搭配Channel的memory或file类型,Sink的logger或hdfs类型进行Flume配置实验。
实验一:exec_mem_logger.conf
#定义各个组件
agent1.sources = src
agent1.channels = ch
agent1.sinks = des
#配置source
agent1.sources.src.type = exec
agent1.sources.src.command = tail -n 20 /data/flume2/goods
#配置channel
agent1.channels.ch.type = memory
#配置sink
agent1.sinks.des.type = logger
##下面是把上面设置的组件关联起来(把点用线连起来)
agent1.sources.src.channels = ch
agent1.sinks.des.channel = ch
启动flume命令:
flume-ng agent -c /conf -f /apps/flume/conf/exec_mem_logger.conf -n agent1 -Dflume.root.logger=DEBUG,console
参数说明:
#source:exec、channel:memory、 sink:logger
-c 配置文件存放的目录
-f 所使用的配置文件路径
-n agent的名称
开启flume后,查看输出效果
source:exec,channel:memory,sink:hdfs。 相对于上一个实验,它的Sink类型发生了变化,变成了hdfs型。其结构中定义的各组件,Source配置没有变,在配置Channel时最大容量capacity为100000,通信的最大容量为100,在配置Sink时类型变为hdfs,/%Y/%m/%d,里面的%Y/%m/%d代表年月日,数据类型为文本型,写入格式为Text格式,写入hdfs的文件是否新建有几种判断方式:rollInterval表示基于时间判断,单位是秒,当为0时,表示不基于时间判断。rollSize表示基于文件大小判断,单位是B,当为0时表示不基于大小判断,rollCount表示基于写入记录的条数来判断,当为0时,表示不基于条数来判断。idleTimeout表示基于空闲时间来判断,单位是秒,当为0时,代表不基于空闲时间来判断。最后上次一样通过设置Source和Sink的Channel都为ch,把Source、Channel和Sink三个组件关联起来。
实验二:exec_mem_hdfs.conf
#定义各个组件
agent1.sources = src
agent1.channels = ch
agent1.sinks = des
#配置source
agent1.sources.src.type = exec
agent1.sources.src.command = tail -n 20 /data/flume2/goods
#配置channel
agent1.channels.ch.type = memory
agent1.channels.ch.keep-alive = 30
agnet1.channels.ch.capacity = 1000000
agent1.channels.ch.transactionCapacity = 100
#配置sink
agent1.sinks.des.type = hdfs
agent1.sinks.des.hdfs.path = hdfs://localhost:9000/myflume2/exec_mem_hdfs/%Y%m%d/
agent1.sinks.des.hdfs.useLocalTimeStamp = true
#设置flume临时文件的前缀为 . 或 _ 在hive加载时,会忽略此文件。
agent1.sinks.des.hdfs.inUsePrefix=_
#设置flume写入文件的前缀是什么
agent1.sinks.des.hdfs.filePrefix = abc
agent1.sinks.des.hdfs.fileType = DataStream
agent1.sinks.des.hdfs.writeFormat = Text
#hdfs创建多久会新建一个文件,0为不基于时间判断,单位为秒
agent1.sinks.des.hdfs.rollInterval = 30
#hdfs写入的文件达到多大时,创建新文件 0为不基于空间大小,单位B
agent1.sinks.des.hdfs.rollSize = 100000
#hdfs有多少条消息记录时,创建文件,0为不基于条数判断
agent1.sinks.des.hdfs.rollCount = 10000
#hdfs空闲多久就新建一个文件,单位秒
agent1.sinks.des.hdfs.idleTimeout = 30
##下面是把上面设置的组件关联起来(把点用线连起来)
agent1.sources.src.channels = ch
agent1.sinks.des.channel = ch
启动flume命令:
flume-ng agent -c /conf -f /apps/flume/conf/exec_mem_hdfs.conf -n agent1 -Dflume.root.logger=DEBUG,console
在另一窗口,查看HDFS上的输出hadoop fs -ls -R /myflume2