
数据转移工具Sqoop
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql…)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。Apache框架Hadoop是一个越来越通用的分布式计算环境,主要用来处理大数据。随着云提供商利用这个框架,更多的用户将数据集在Hadoop和传统数据库之间转移,Sqoop这个帮助数据传输的工具变得更加重要。
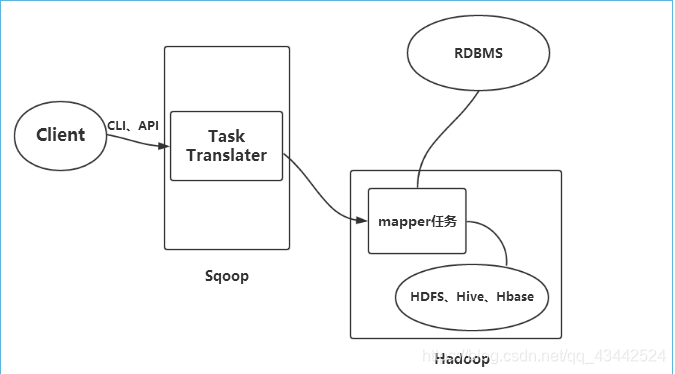
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(Mysql、Oracle…)间进行数据的传递,可以将一个关系型数据库中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导入到关系型数据库中。
特点:
- 可导入单个或者所有数据库中的表格
- 可以通过WHERE指定导入的行 列
- 可以提供任意的SELECT语句
- 可以自动生成一个Hive表格, 根据输入的数据
- 可以支持增长性的数据导入
- 可以将HDFS导出到其他数据库
- 支持文本文件(–as-textfile)、avro(–as-avrodatafile)、SequenceFiles(–as-sequencefile)。
工作原理
Sqoop检查每一个table并且自动生成一个Java class来导入数据到HDFS
Sqoop会产生和运行一个Map-only的MapReduce job来导入数据
默认会有4个Mapper连接到RDBMS, 每一个导入1/4数据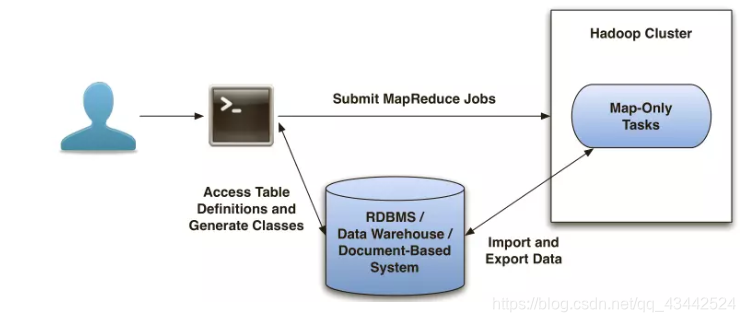
Sqoop Connectors
自定义Sqoop connectors提供更高速的访问;
目前支持Netezza, Teradata, Oracle Database
Sqoop2:

sqoop和sqoop2的区别:

当HDFS有数据写入时, NameNode会把文件标记为存在, 但是size = 0
当每一份block写入后, 其他的clients会看到block
为了避免多人同时访问同一份数据, 最好是先将数据导入到一个临时目录;
当文件完全写入后, 将其一直目标文件夹(atomic操作), 因为这个操作只需要NameNode更新一下metaData, 所以也很快;
一些机构标准的注释方式:
./incoming/...
./for_processing/...
./completed/...
REST接口也可以访问HDFS
WebHDFS, HttpFS