
列表 元组 字典 集合的区别
列表:清单可重复,类型可不同 list
元组: 类似列表不可修改类型 tuple
集合:就是我们数学学的集合应用是去重 set
字典:字典存储键值对数据价值是查询,通过键,查找值 dict
列表
列表的特点:可重复,类型可不同,这是与数组最本质的区别。
python中的列表用“[]”表示
list=[‘asd’,123]
向list中添加项有两种方法:append和extend。append
使用append可能会出现下面的这种情况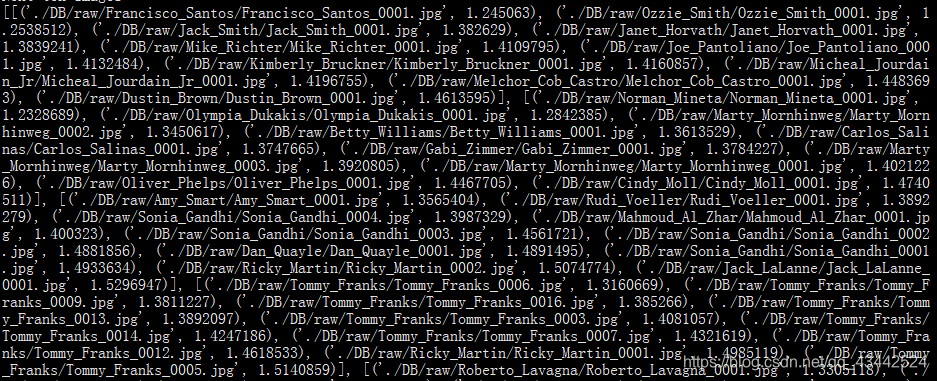
列表里会叠加列表
这是使用extend就不会出现这种问题
元组
元组和列表在结构上没有什么区别,唯一的差异在于元组是只读的,不能修改。
元组用“()”表示,如:
tup =(‘asd’,123)
元组可以使用切片,例如tup[0]
集合
集合就是我们数学学的集合,没有什么特殊的定义。集合最好的应用是去重。
list = [ 1, 11, 1]
list_set = set( list ) #lst_set 为1 , 11
字典
最后一个是字典。字典存储键值对数据,{key:value},如:
{1:a,2:b,3:c}
字典最外面用大括号,每一组用冒号连起来,然后各组用逗号隔开。
字典最大的价值是查询,通过key,查找value。
转换
字典
dict = {‘a’: ‘1’, ‘b’: 2, ‘c’: ‘3’}
将该字典转换为字符串
str(dict)
返回:
{‘a’: ‘1’, ‘b’: 2, ‘c’: ‘3’}(注:这里虽然看着一样,但其实字典已经变为字符串,可以使用type(dict)查看)
将该字典转为元组
tuple(dict)
返回:
(‘a’,’b’,’c’)
将该字典values值转为元组
tuple(dict.values())
返回:
(‘1’,’2’,’3’)
将该字典转为列表
(list(dict))
[‘a’,’b’,’c’]
元组
tup=(1, 2, 3, 4, 5)
将元组转为字符串,返回:(1, 2, 3, 4, 5)
(tup.str()
将元组转为列表,返回:[1, 2, 3, 4, 5]
list(tup)
元组不可以转为字典
列表
nums=[1, 3, 5, 7, 8, 13, 20]
将列表转为字符串,返回:[1, 3, 5, 7, 8, 13, 20]
str(nums)
将列表转为元组,返回:(1, 3, 5, 7, 8, 13, 20)
tuple(nums)
列表不可以转为字典
字符串
将字符串转为元组,返回:(1, 2, 3)
tuple(eval(“(1,2,3)”))
将字符串转为列表,返回:[1, 2, 3]
list(eval(“(1,2,3)”))
#字符串转为字典,返回:
type(eval(“{‘name’:’ljq’, ‘age’:24}”))
排序
字典
创建一个字典
dict1={‘a’:2,’b’:3,’c’:8,’d’:4}
1、取字典的所有键,所有的值,利用dict1.keys(),dict1.vaules(),
由于键,值有很多个,所以要加s,另外注意这里要加括号,这样的小细节不注意,很容易犯错。
结果:
dict_values([4, 2, 8, 3]) dict_keys([‘d’, ‘a’, ‘c’, ‘b’])
可以看出,返回的是列表的形式
2、同时取字典的键、值,dict1.items(),这里同样加s和括号
print(dict1.items())
结果:
dict_items([(‘d’, 4), (‘a’, 2), (‘c’, 8), (‘b’, 3)])
可以看出,返回的结果是元组组成的列表
也就是说,通过dict1.items()这个函数,把字典形式的键、值,存在了一个元组内。
3、对字典进行排序
3.1 先看一下,直接用sorted()排序的情况。
dict1={‘a’:2,’e’:3,’f’:8,’d’:4}
dict2 = sorted(dict1)
print(dict2)
结果:
[‘a’, ‘d’, ‘e’, ‘f’]
sorted()默认是对字典的键,从小到大进行排序
3.2 、对键值进行反向(从大到小)排序
dict1={‘a’:2,’e’:3,’f’:8,’d’:4}
dict2 = sorted(dict1,reverse=True)
print(dict2)
结果:[‘f’, ‘e’, ‘d’, ‘a’]
像这种对键进行排序,往往是为了得到 值(value)
拿到键最大,对应的值,如:
print(dict1[dict2[0]])#结果为8
当然我们也可以先拿到所有的key,然后再对key排序
dict1={‘a’:2,’e’:3,’f’:8,’d’:4}
list1= sorted(dict1.keys(),reverse=True)
print(list1) # 结果:[‘f’, ‘e’, ‘d’, ‘a’]
3.3、对value进行排序
同样,用dict1.values()得到所有的values,然后对value排序
dict1={‘a’:2,’e’:3,’f’:8,’d’:4}
list1= sorted(dict1.values())
print(list1) #结果:[2, 3, 4, 8]
设值reverse=True 进行反向排序
也可以用dict1.items(),得到包含键,值的元组
由于迭代对象是元组,返回值自然是元组组成的列表
这里对排序的规则进行了定义,x指元组,x[1]是值,x[0]是键
dict1={‘a’:2,’e’:3,’f’:8,’d’:4}
list1= sorted(dict1.items(),key=lambda x:x[1])
print(list1)
结果:
[(‘a’, 2), (‘e’, 3), (‘d’, 4), (‘f’, 8)]
对键进行排序:
dict1={‘a’:2,’e’:3,’f’:8,’d’:4}
list1= sorted(dict1.items(),key=lambda x:x[0])
print(list1)
结果:
[(‘a’, 2), (‘d’, 4), (‘e’, 3), (‘f’, 8)]
列表
基本的列表排序
1.list.sort()排序
data = [5, 7, 9, 3, -6, -7, -8, -9, 3, -8]
result = data.sort()
print(data) #结果为 [-9, -8, -8, -7, -6, 3, 3, 5, 7, 9]
print(result) #结果为None
1
2
3
4
2.sorted()排序
data = [5, 7, 9, 3, -6, -7, -8, -9, 3, -8]
result = sorted(data)
print(data) #结果为 [5, 7, 9, 3, -6, -7, -8, -9, 3, -8]
print(result) #结果为 [-9, -8, -8, -7, -6, 3, 3, 5, 7, 9]
当元组最为list的元素时
在默认情况下sort和sorted函数接收的参数是元组时,它将会先按元组的第一个元素进行排序再按第二个元素进行排序,再按第三个、第四个…依次排序。
我们通过一个简单的例子来了解它,以下面这个list为例:data = [(1, 'B'), (1, 'A'), (2, 'A'), (0, 'B'), (0, 'a')]
我们通过sorted()对它进行排序1
2
3
4data = [(1, 'B'), (1, 'A'), (2, 'A'), (0, 'B'), (0, 'a')]
result = sorted(data)
print(data) #结果为 [(1, 'B'), (1, 'A'), (2, 'A'), (0, 'B'), (0, 'a')]
print(result) #结果为 [(0, 'B'), (0, 'a'), (1, 'A'), (1, 'B'), (2, 'A')]
会发现排序后的结果中(0, ‘B’)在(0, ‘a’)的前面。这是因为在按元组第一个元素排好之后,将(0, ‘B’), (0, ‘a’)再按第二个元素进行排序了,而’B’的ASCII编码比’a’小,所以(0, ‘B’)就排在(0, ‘a’)的前面了。
那如何想要让它排序时不分大小写呢?
这就要用到sort方法和sorted方法里的key参数了。
我们来看一下具体的实现:1
2
3
4
5
6data = [(1, 'B'), (1, 'A'), (2, 'A'), (0, 'B'), (0, 'a')]
#利用参数key来规定排序的规则
result = sorted(data,key=lambda x:(x[0],x[1].lower()))
print(data) #结果为 [(1, 'B'), (1, 'A'), (2, 'A'), (0, 'B'), (0, 'a')]
print(result) #结果为 [(0, 'a'), (0, 'B'), (1, 'A'), (1, 'B'), (2, 'A')]
其中的lambda x:(x[0],x[1].lower())可以理解为一个匿名函数;
其功能类似于:1
2def fun(x)
return(x[0],x[1].lower())
如果想要以字母作为第一排序规则,并且字母大小写不敏感,该怎么实现?
这就能要运用到之前所讲到的
在默认情况下sort和sorted函数接收的参数是元组时,它将会先按元组的第一个元素进行排序再按第二个元素进行排序,再按第三个、第四个…依次排序。
再配合lambda返回一个自定义tuple;代码如下:1
2
3
4
5
6data = [(1, 'B'), (1, 'A'), (2, 'A'), (0, 'B'), (0, 'a')]
将x[1].lower()作为返回元组里的第一个元素,按照sorted的排序规律,就会先按字母排序,再按数字排序了
result = sorted(data,key=lambda x:(x[1].lower(),x[0]))
print(data) #结果为 [(1, 'B'), (1, 'A'), (2, 'A'), (0, 'B'), (0, 'a')]
print(result) #结果为 [(0, 'a'), (1, 'A'), (2, 'A'), (0, 'B'), (1, 'B')]
当字典作为列表的元素时
1 | data = [{'name': '张三', 'height': 175}, {'name': '李四', 'height': 165}, {'name': '王五', 'height': 185}] |