分布式消息系统Kafka
Kafka可以处理消费者规模的网站中的所有动作流数据。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息
kafka是一个分布式的、可分区的、可复制的消息系统;
kafka是由LinkedIn开发,使用Scala编写;
支持水平拓展和高吞吐率;
可与Apache Storm、Spark等多种开源分布式处理系统集成。
相关知识:
(1)以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间复杂度的访问性能
(2)高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条以上消息的传输
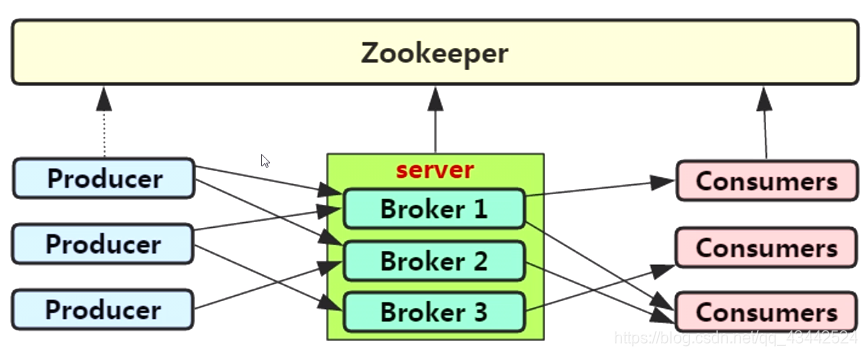
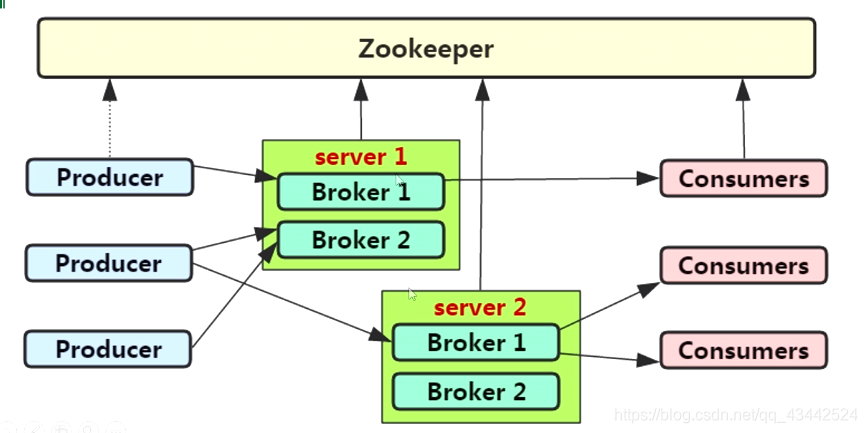
(3)支持Kafka Server间的消息分区,及分布式消费,同时保证每个Partition内的消息顺序传输
(4)同时支持离线数据处理和实时数据处理
(5)Scale out:支持在线水平扩展
Kafka中各个组件的功能:
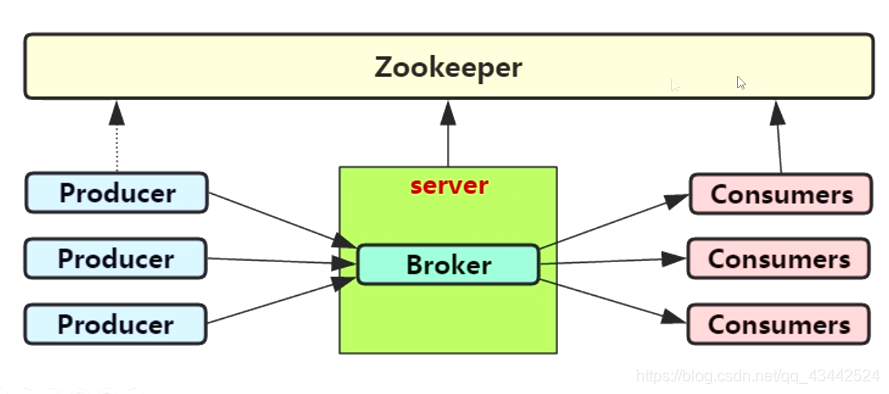
(1)Broker: Kafka集群包含一个或多个服务器,这种服务器被称为broker
(2)Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上,但用户只需指定消息的Topic即可生产或消费数据,不必关心数据存于何处)
(3)Partition:Parition是物理上的概念,每个Topic包含一个或多个Partition
(4)Producer:负责发布消息到Kafka broker
(5)Consumer:消息消费者,向Kafka broker读取消息的客户端
(6)Consumer Group:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)
Kafka应用场景
活动数据包括页面访问量、被查看内容方面的信息以及搜索情况等内容
构建应用系统和分析系统的桥梁,并将它们之间的关联解耦;
支持近实时的在线分析系统和类似于Hadoop之类的离线分析系统;
具有高可扩展性。即:当数据量增加时,可以通过增加节点进行水平扩展。
Kafka与Flume
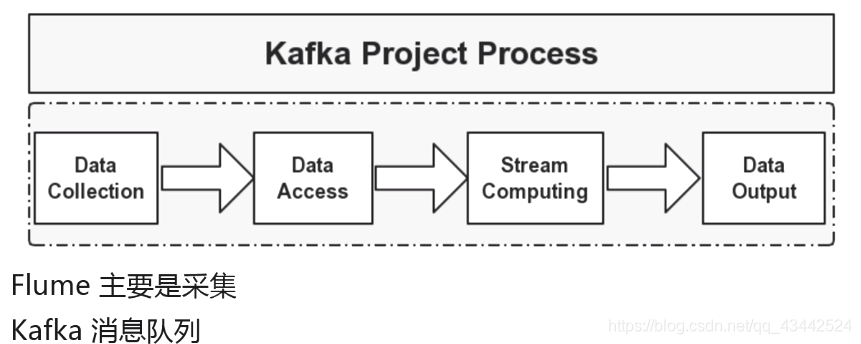
Kafka与Flume联用
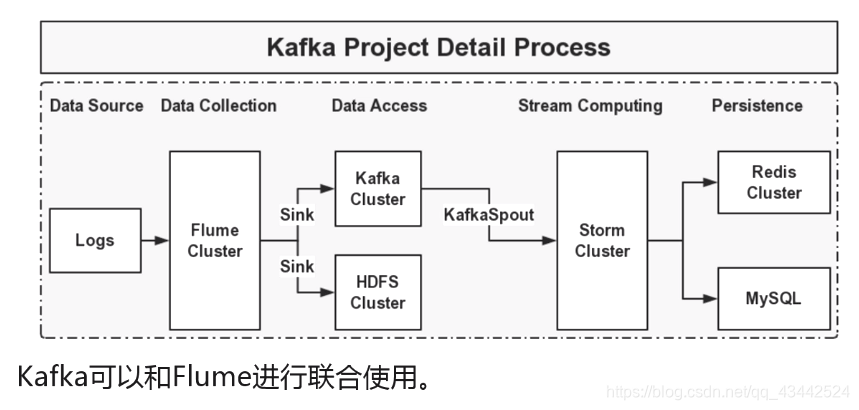
Kafka的模型
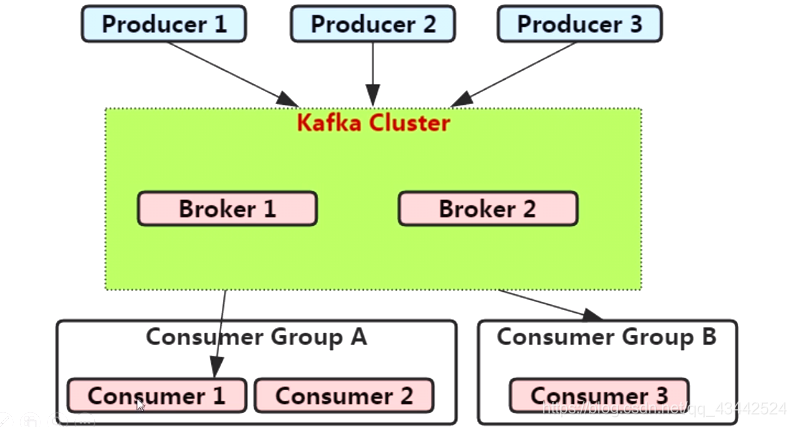
Kafka的名词说明

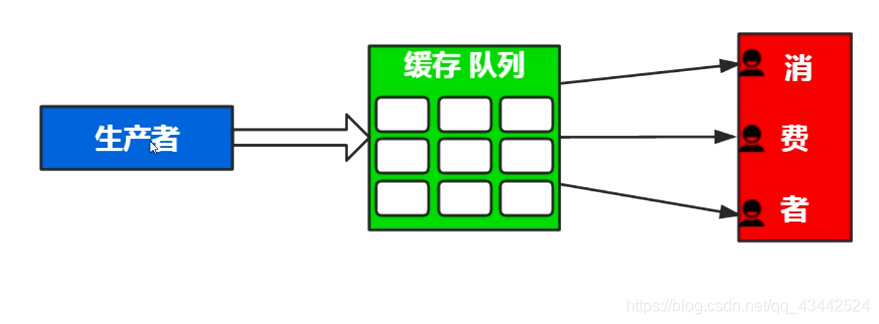
生产者/消费者模式
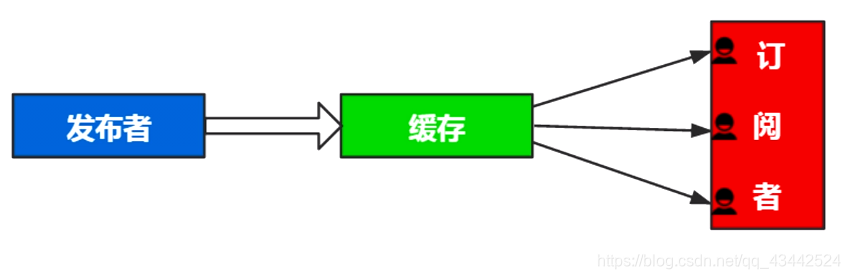
发布/订阅模式
模型
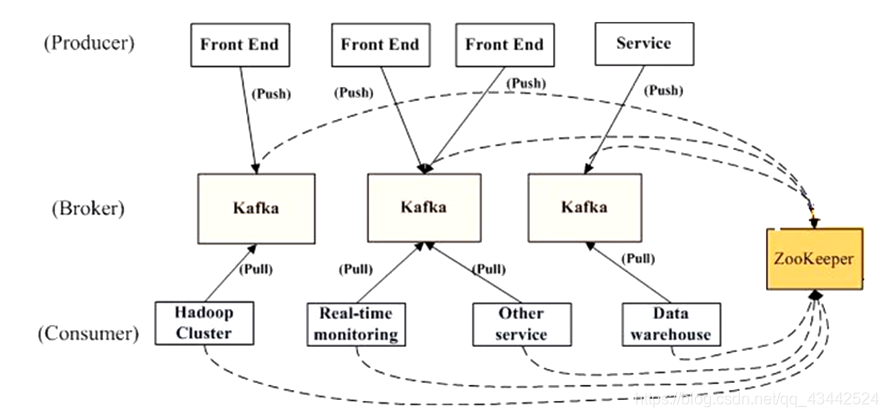
Push和Pull(拉数据)
Consumer自己选择拉数据
优点

环境部署