
Spark 简介
Spark shell是一个特别适合快速开发Spark程序的工具。即使你对Scala不熟悉,仍然可以使用这个工具快速应用Scala操作Spark。
Spark shell使得用户可以和Spark集群交互,提交查询,这便于调试,也便于初学者使用Spark。
Spark shell是非常方便的,因为它很大程度上基于Scala REPL(Scala交互式shell,即Scala解释器),并继承了Scala REPL(读取-求值-打印-循环)(Read-Evaluate-Print-Loop)的所有功能。运行spark-shell,则会运行spark-submit,spark-shell其实是对spark-submit的一层封装。
下面是Spark shell的运行原理图
RDD
RDD有两种类型的操作 ,分别是Transformation(返回一个新的RDD)和Action(返回values)。
1.Transformation:根据已有RDD创建新的RDD数据集build
(1)map(func):对调用map的RDD数据集中的每个element都使用func,然后返回一个新的RDD,这个返回的数据集是分布式的数据集。
(2)filter(func) :对调用filter的RDD数据集中的每个元素都使用func,然后返回一个包含使func为true的元素构成的RDD。
(3)flatMap(func):和map很像,但是flatMap生成的是多个结果。
(4)mapPartitions(func):和map很像,但是map是每个element,而mapPartitions是每个partition。
(5)mapPartitionsWithSplit(func):和mapPartitions很像,但是func作用的是其中一个split上,所以func中应该有index。
(6)sample(withReplacement,faction,seed):抽样。
(7)union(otherDataset):返回一个新的dataset,包含源dataset和给定dataset的元素的集合。
(8)distinct([numTasks]):返回一个新的dataset,这个dataset含有的是源dataset中的distinct的element。
(9)groupByKey(numTasks):返回(K,Seq[V]),也就是Hadoop中reduce函数接受的key-valuelist。
(10)reduceByKey(func,[numTasks]):就是用一个给定的reduce func再作用在groupByKey产生的(K,Seq[V]),比如求和,求平均数。
(11)sortByKey([ascending],[numTasks]):按照key来进行排序,是升序还是降序,ascending是boolean类型。
Action
Action:在RDD数据集运行计算后,返回一个值或者将结果写入外部存储
(1)reduce(func):就是聚集,但是传入的函数是两个参数输入返回一个值,这个函数必须是满足交换律和结合律的。
(2)collect():一般在filter或者足够小的结果的时候,再用collect封装返回一个数组。
(3)count():返回的是dataset中的element的个数。
(4)first():返回的是dataset中的第一个元素。
(5)take(n):返回前n个elements。
(6)takeSample(withReplacement,num,seed):抽样返回一个dataset中的num个元素,随机种子seed。
(7)saveAsTextFile(path):把dataset写到一个textfile中,或者HDFS,或者HDFS支持的文件系统中,Spark把每条记录都转换为一行记录,然后写到file中。
(8)saveAsSequenceFile(path):只能用在key-value对上,然后生成SequenceFile写到本地或者Hadoop文件系统。
(9)countByKey():返回的是key对应的个数的一个map,作用于一个RDD。
(10)foreach(func):对dataset中的每个元素都使用func。
数据说明
某电商网站记录了大量的用户对商品的收藏数据,并将数据存储在名为buyer_favorite的文本文件中。文本数据格式如下:
用户id(buyer_id),商品id(goods_id),收藏日期(dt)
用户id 商品id 收藏日期
10181 1000481 2010-04-04 16:54:31
20001 1001597 2010-04-07 15:07:52
20001 1001560 2010-04-07 15:08:27
20042 1001368 2010-04-08 08:20:30
20067 1002061 2010-04-08 16:45:33
20056 1003289 2010-04-12 10:50:55
20056 1003290 2010-04-12 11:57:35
20056 1003292 2010-04-12 12:05:29
20054 1002420 2010-04-14 15:24:12
20055 1001679 2010-04-14 19:46:04
20054 1010675 2010-04-14 15:23:53
20054 1002429 2010-04-14 17:52:45
20076 1002427 2010-04-14 19:35:39
20054 1003326 2010-04-20 12:54:44
20056 1002420 2010-04-15 11:24:49
20064 1002422 2010-04-15 11:35:54
20056 1003066 2010-04-15 11:43:01
20056 1003055 2010-04-15 11:43:06
20056 1010183 2010-04-15 11:45:24
20056 1002422 2010-04-15 11:45:49
20056 1003100 2010-04-15 11:45:54
20056 1003094 2010-04-15 11:45:57
20056 1003064 2010-04-15 11:46:04
20056 1010178 2010-04-15 16:15:20
20076 1003101 2010-04-15 16:37:27
20076 1003103 2010-04-15 16:37:05
20076 1003100 2010-04-15 16:37:18
20076 1003066 2010-04-15 16:37:31
20054 1003103 2010-04-15 16:40:14
20054 1003100 2010-04-15 16:40:16
环境准备
打开hadoop与spark集群,在命令行输入spark-shell打开sparkshell模式
将数据上传到hdfs中1
2hadoop fs -mkdir -p /myspark3/wordcount
hadoop fs -put /data/spark3/wordcount/buyer_favorite /myspark3/wordcount
统计
要求统计用户收藏数据中,每个用户收藏商品数量
编写Scala语句,统计用户收藏数据中,每个用户收藏商品数量。
先在spark-shell中,加载数据。val rdd = sc.textFile("hdfs://localhost:9000/myspark3/wordcount/buyer_favorite");
执行统计并输出。rdd.map(line=> (line.split('\t')(0),1)).reduceByKey(_+_).collect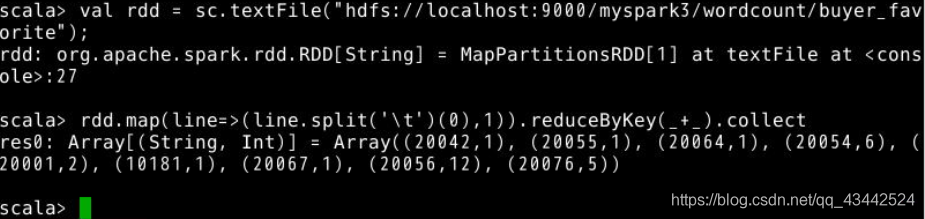
sc是在进入spark shell 时候创建一个spark content 就是spark上下文的意思,val 是scala语法中声明常量的方式,通过println我们可以看到读入的文件被处理成一个MappedRDD的对象 mapred相信学过hadoop的人都不会陌生,RDD是Resilient Distributed Datasets,是一种弹性分布式数据集。
关于reduceByKey
reduceByKey(_ ++ _) is equivalent to reduceByKey((x,y)=> x ++ y) reduceByKey takes two parameters, apply a function and returns
At the first it crates a set and ++ just adds collections together, combining elements of both sets.
For each key It keeps appending in the list. In your case of 1 as a key x will be List(2,3) and y will List (3,4) and ++ will add both as List (2,3,3,4)
If you had another value like (1,4,5) then the x would be List(4,5) in this case and y should be List (2,3,3,4) and result would be List(2,3,3,4,4,5)