
详细搭建可以参考我的Hadoop2.8.0安装
准备
本文下载的是3.1.3版本的Hadoop
关闭防火墙1
2systemctl stop firewalld
setenforce 0
虚拟机的准备
安装3个虚拟机并实现ssh免密码的登录
安装3个centos7虚拟机
安装3个机器,机器分别叫master slave1 slave2
在/etc/hostname下修改主机名
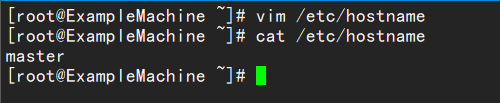
其他两台也是一样
修改主机映射
修改/etc/hosts文件
修改这3台机器的/etc/hosts文件,在文件中添加以下内容,如图:

说明:ip地址没必要和我的一样,这里只是做一个映射,只要映射是对的就可以,至于修改方法,vi vim 命令都可以。
配置成功后使用 ping 命令检查者3台机器是否相互ping的通,以master为例
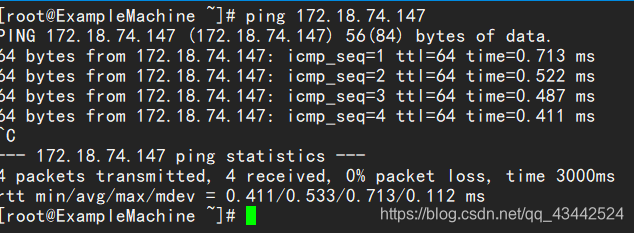
使用该命令 在各个机器都尝试是否可以ping通,ping得通,说明机器是互联的,而且hosts配置也正确。
配置免密
给3个机器生成秘钥文件
以master为例,执行命令,生成空字符串的秘钥(后面要使用公钥),命令是:
ssh-keygen -t rsa
使用相同的方法为slave1与slave2生成秘钥(命令相同,不用做任何修改)。
在master上创建authorized_keys文件
接下来要做的事情就是在3台机器的/root/.shh/目录下都存入一个内容相同的文件,文件名称叫authorized_keys,文件内容是我们刚才为3台机器生成的公钥。
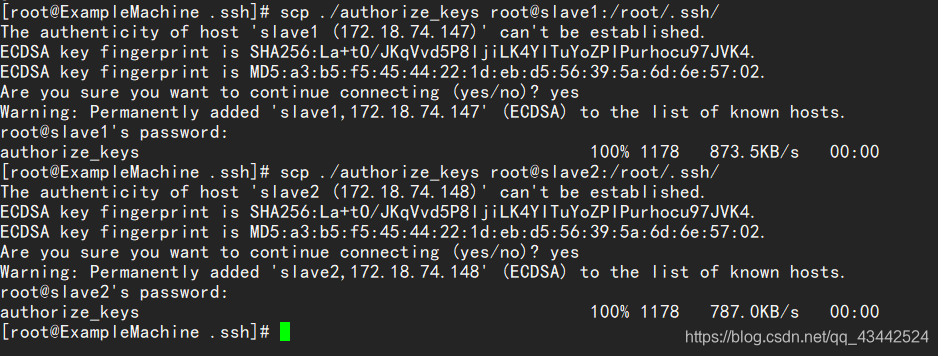
为了方便,我下面的步骤是现在master上生成authorized_keys文件,然后把3台机器刚才生成的公钥加入到这个master的authorized_keys文件里,然后在将这个authorize_keys文件复制到slave1与slave2里。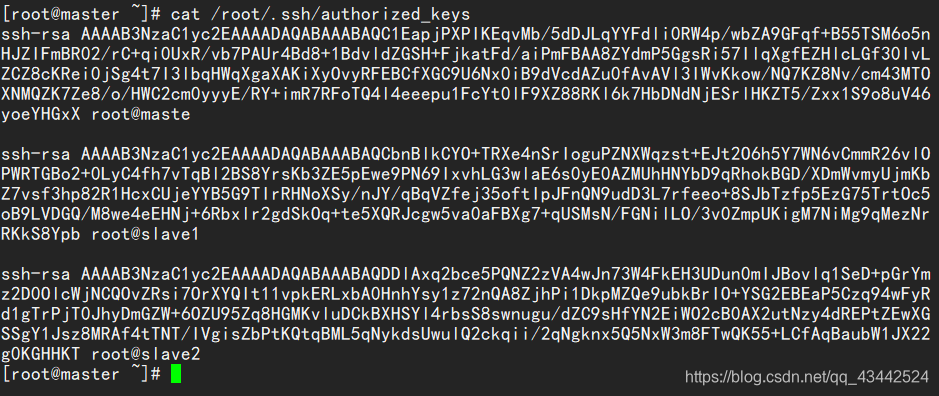
安装JDK
详细的JDK安装
创建java目录
mkdir /usr/local/jdk
下载jdk1.8版本,并将其解压到/usr/local/java目录下
tar -zxvf jdk-8u201-linux-x64.tar.gz -C /usr/local/jdk
1 | #JAVA |
传输到其他节点scp -r /usr/local/jdk/ root@slave1:/usr/local/scp -r /usr/local/jdk/ root@slave2:/usr/local/
安装Hadoop
解压缩Hadoop3.1.3到cd /usr/local/hadoop/
配置Hadoop3.1.1
修改环境变量1
2
3
4
5
#hadoop environment
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
scp /etc/profile root@slave1:/etc/scp /etc/profile root@slave2:/etc/
创建目录
#在/usr/local/hadoop目录下创建目录
cd /usr/local/hadoop/
mkdir tmp
mkdir var
mkdir dfs
mkdir dfs/name
mkdir dfs/data

修改配置文件
进入hadoop的配置文件目录下cd /usr/local/hadoop/hadoop-3.1.3/etc/hadoop
vi workers
删除localhost
添加从节点主机名,例如我这里是:
slave1
slave2
hadoop-env.sh
在# JAVA_HOME=/usr/java/testing hdfs dfs -ls后添加
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_201
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.3
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/dfs/name</value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>need not permissions</description>
</property>
</configuration>
yarn-site.xml
在命令行下输入如下命令,并将返回的地址复制,在配置下面的yarn-site.xml时会用到。
hadoop classpath
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>输入刚才返回的Hadoop classpath路径</value>
</property>
mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>master:49001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/usr/local/hadoop/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
同步
使用scp命令将master下的目录复制到各个从节点的相应位置上scp -r /usr/local/hadoop/ root@slave1:/usr/local/scp -r /usr/local/hadoop/ root@slave2:/usr/local/
Hadoop启动
格式化节点
在master中运行下述命令,格式化节点
hadoop namenode -format
运行之后不报错,并在倒数第五六行有successfully即为格式化节点成功
运行以下命令,启动hadoop集群的服务
在sbin目录下运行start-all.sh
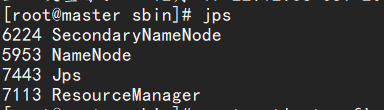
在master上输入jps可以看到master下的节点
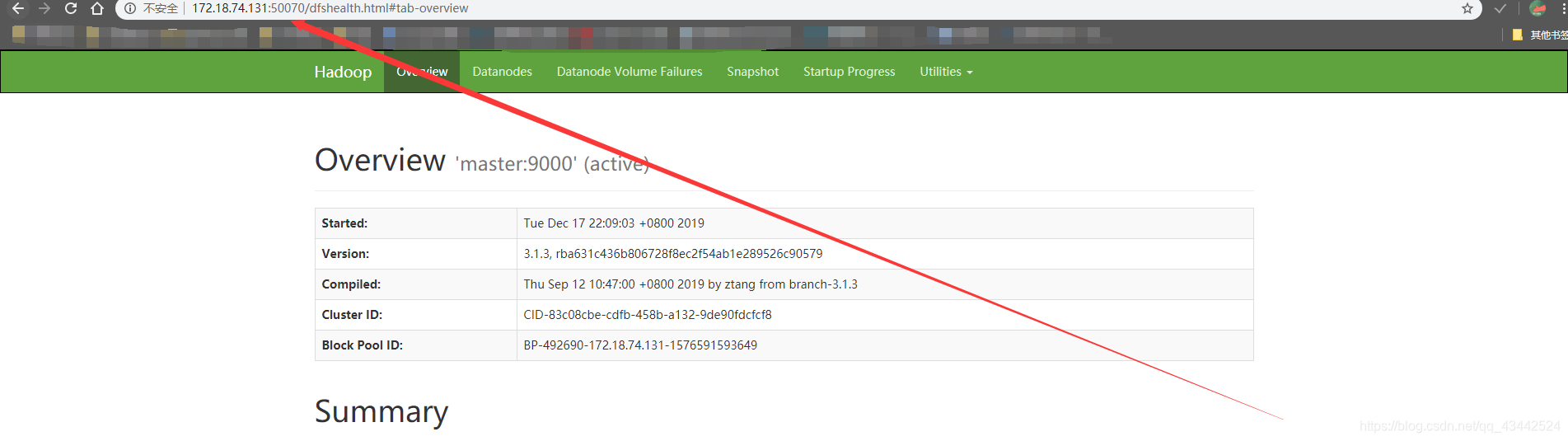
在浏览器输入http://172.18.74.131:50070/进入web模式
运行wordcount程序
hdfs上创建文件夹
hadoop fs -mkdir -p /data/input
在本地创建一个wordcount.txt,并编辑
随便输入一些字符
把本地的wordcount.txt文件上传到hdfs,并且查看是否存在
hadoop fs -put wordcount.txt /data/input
hadoop fs -ls /data/input
运行share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar
在hadoop_home的目录下执命令:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /data/input/wordcount.txt /data/out/my_wordcount
查看hdfs的/data/output/my_wordcount/part-r-00000文件。
hadoop fs -cat /data/out/my_wordcount/part-r-00000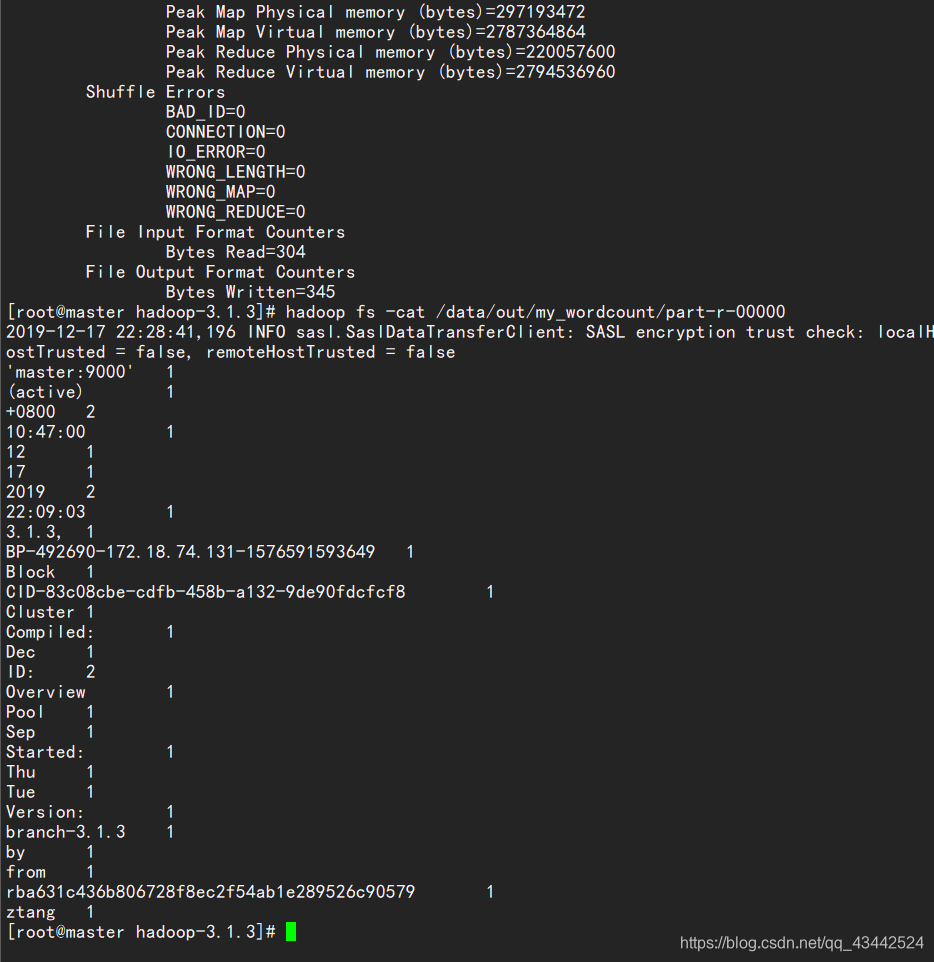
统计字数成功!